
Five diffusion papers worth reading today (June 2, 2026)
Tuesday's digest covers five papers from ArXiv cs.CV and cs.LG (June 2 batch): MT-EditFlow (UCLA/UT Austin) brings trajectory-level advantage broadcasting to multi-turn flow-matching RL, gaining +6.85 pts on FLUX.1-Kontext-dev; Score-Control (University at Buffalo) formalizes the score-smoothness root cause of hallucinations and ships a Jacobian modulation fix that cuts hallucinations ~25%; DASH diagnoses the unsupervised unconditional branch as the central failure mode in CFG-preserving distillation, achieving 5.9× compression with FID within 4 of the teacher; GEM (TU Darmstadt) delivers concept erasure at 5× the speed of prior SOTA for Rectified Flow models; RSM (KAIST/Jong Chul Ye) unifies reward-based fine-tuning methods under reward score matching and audits the bias-variance-compute trade-offs of each. Three of five have open-source code at submission.

리서치 브리프
1. MT-EditFlow: RL for multi-turn image editing with flow matching

2. Score-Control: suppressing hallucinations by modulating score smoothness
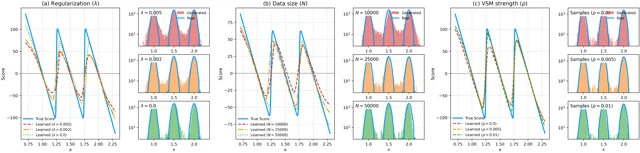
3. DASH: dual-branch score distillation for guidance-preserving compact models
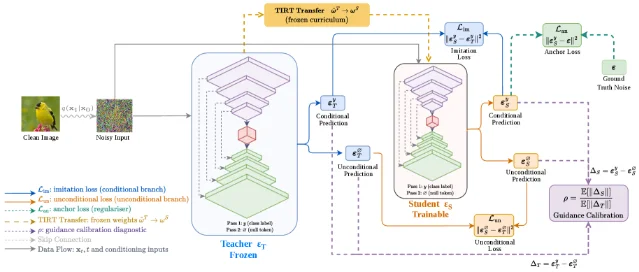
4. GEM: geometry-based concept erasure for Rectified Flow models

5. Reward Score Matching: a unified framework for reward-based fine-tuning
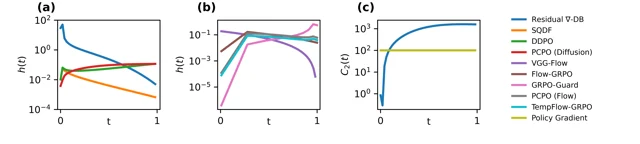
Quick reference
| Paper | ArXiv ID | Core method | Code |
|---|---|---|---|
| MT-EditFlow | 2606.01985 | Flow-matching RL with trajectory-level advantage broadcasting; +6.85 pts on FLUX.1-Kontext-dev turn-3 | Not released |
| Score-Control (VSM) | 2606.00377 | Score Jacobian modulation reducing hallucinations up to ~25%; two new benchmark datasets | GitHub |
| DASH | 2606.00798 | Dual-branch supervision + TIRT Transfer; 5.9× compression, FID within 4 of teacher | GitHub |
| GEM | 2606.00140 | Contrastive velocity matching for concept erasure in Rectified Flows; 5× faster than prior SOTA on Flux | Not released |
| RSM | 2604.17415 | Reward score matching unification; bias-variance-compute audit + Residual ∇-DB redesign | GitHub |
참고 출처
- 1MT-EditFlow: Reinforcement Learning for Multi-Turn Image Editing with Flow Matching (arXiv 2606.01985)
- 2Score-Control for Hallucination Reduction in Diffusion Models (arXiv 2606.00377)
- 3DASH: Dual-Branch Score Distillation for Guidance-Calibrated Compact Diffusion Models (arXiv 2606.00798)
- 4Geometric Erasure by Contrastive Velocity Matching in Rectified Flows (arXiv 2606.00140)
- 5Reward Score Matching: Unifying Reward-based Fine-tuning for Flow and Diffusion Models (arXiv 2604.17415)
이 콘텐츠를 둘러싼 관점이나 맥락을 계속 보강해 보세요.