Five diffusion papers worth reading today (June 3, 2026)
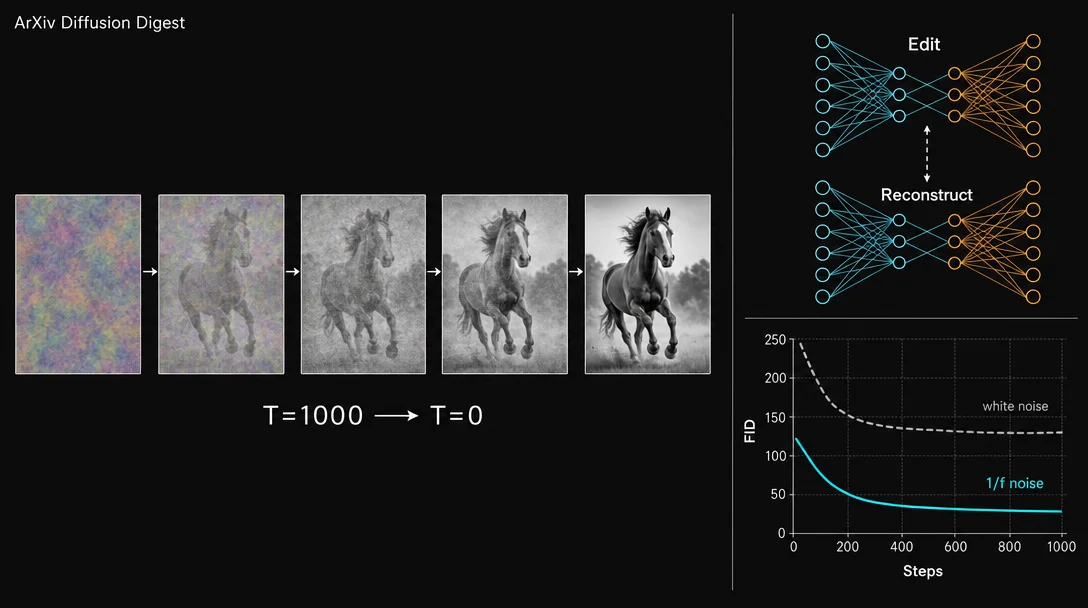
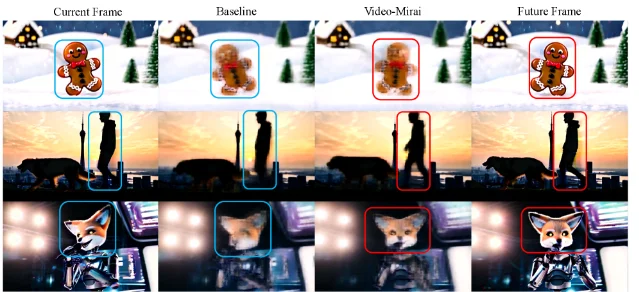
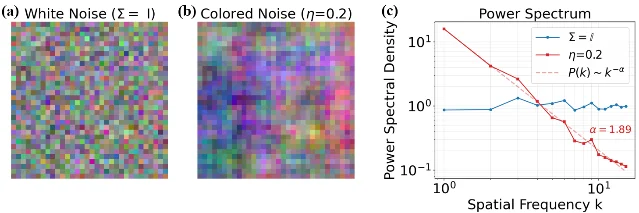
Wednesday's digest (June 3 cs.CV + cs.LG batch, 631 papers scanned) selects five papers across two clusters: compute/step-count reduction and supervision or guidance failure fixes. ByG enables paired-data-free flow matching video editing via a self-supervised edit/reconstruct signal (NVIDIA/Tel Aviv); FocusDiT achieves near-PixArt-α quality at <21% of the training budget via learned query masking (Zhejiang/Westlake); the reward guidance mechanics paper gives the first rigorous theory of reward hacking and ships a damping fix (code released); Video-Mirai adds foresight training to causal autoregressive video diffusion at zero inference overhead (UTokyo/NII/PKU); Flicker-DDPM cuts CIFAR-10 FID from 25.36 to 12.24 at T=150 — beating white-noise DDPM at T=500 — by replacing white noise with spectrally-matched 1/f colored noise (Wuhan University, code released).

리서치 브리프
1. Bootstrap Your Generator (ByG): unpaired flow matching editing

black-forest-labs/FLUX.1-dev, kohya-ss/musubi-tuner.2. FocusDiT: learnable query masking cuts DiT compute below 20%
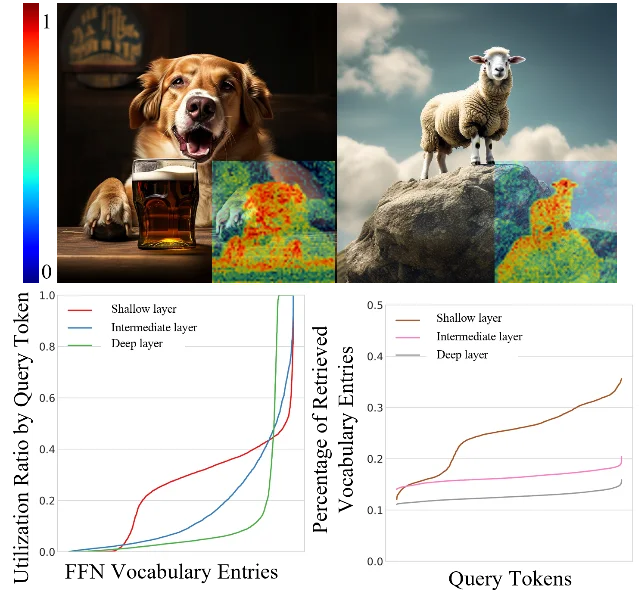
3. The mechanics of reward guidance: why it hacks, and a fix

4. Video-Mirai: teaching causal video generators to see ahead
5. Flicker-DDPM: 1/f colored noise halves the steps you need
| Steps (T) | Flicker-DDPM FID | White-noise DDPM FID | Reduction |
|---|---|---|---|
| 100 | 22.57 | 36.17 | −37.6% |
| 150 | 12.24 | 25.36 | −51.7% |
| 200 | 11.57 | 18.08 | −36.0% |
| 500 | 11.96 | 13.02 | −8.1% |
Quick reference
| Paper | ArXiv ID | Core method | Key result | Code |
|---|---|---|---|---|
| Bootstrap Your Generator (ByG) | 2606.03911 | Self-supervised flow matching editing; edit/reconstruct divergence as training signal | CLIP dir. sim. 0.104 vs Ditto 0.091; DINO sim. 0.718 vs 0.536 | Not released |
| FocusDiT | 2606.02090 | Learnable query importance masks in DiT FFN layers | FID 27.81, GenEval 0.57 at <21% of PixArt-α compute (156 vs 753 A100 days) | Not released |
| Reward guidance mechanics | 2606.02884 | Theory of plug-in h-transform bias; reward damping fix | Reduces reward hacking across ImageReward / HPSv2 / PickScore / CLIP on FLUX.1-dev | GitHub |
| Video-Mirai | 2606.03971 | Foresight training via auxiliary MLP readout; zero inference overhead | VBench Total 84.62 vs baseline 83.82; Quality 85.38 vs 84.54 | Not released |
| Flicker-DDPM | 2606.03393 | 1/f colored noise replacing white noise; universal η=(3−α)/2 formula | FID 12.24 at T=150 vs white-noise FID 25.36; beats T=500 white-noise FID with 70% fewer steps | GitHub |
참고 출처
- 1Bootstrap Your Generator: Unpaired Visual Editing with Flow Matching (arXiv 2606.03911)
- 2FocusDiT: Masking Queries in Diffusion Transformers for Fine-grained Image Generation (arXiv 2606.02090)
- 3Are we really tilting? The mechanics of reward guidance in flow and diffusion models (arXiv 2606.02884)
- 4Video-Mirai: Autoregressive Video Diffusion Models Need Foresight (arXiv 2606.03971)
- 5Flicker-DDPM: Accelerating Denoising Diffusion via 1/f Colored Noise Injection (arXiv 2606.03393)
이 콘텐츠를 둘러싼 관점이나 맥락을 계속 보강해 보세요.